Fácile中文摘要分析
About Our Topic
在現今資訊爆炸的年代,愈來愈多人對閱讀產生抗拒感,也因為社群使用的高黏著性,導致人們閱讀長文章的專注度逐漸降低。藉此,設計可摘要文章之應用,進而提高閱讀效率。
About Our Work
|
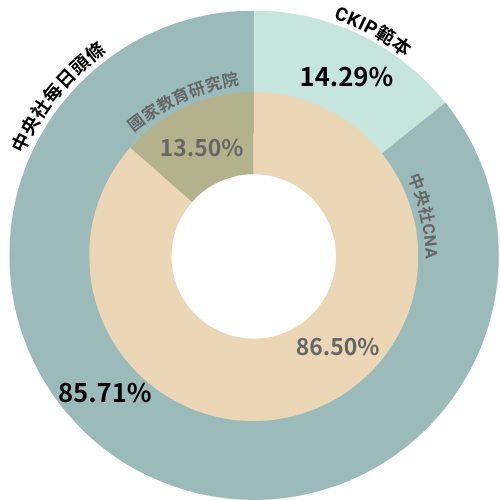
語料來源
在改良語料的選擇上,採用 CKIPTagger 和 Jieba-zh_TW 同樣之中央社語料,並增加國家教育研究院之專業領域名詞作為詞庫擴充,共計 357,042 筆詞。為判斷自訂語料庫架構是否達正向之改善,對比 CKIPTagger 與 Jieba 斷詞,分析輸出差異;藉此,對比文本選擇為CKIP所測試之範例以及CNA每日頭條新聞作為分析標的。 |
|
|
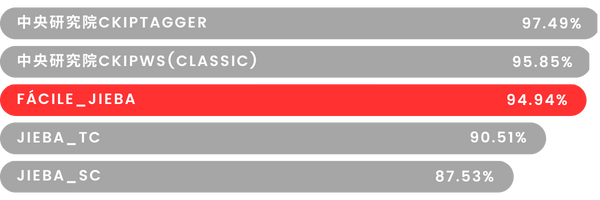
核心1 斷詞分析
在機器學習理論中,精確率愈高、召回率就愈低,反之亦然;因此,透過重新訓練語料庫後,本研究之Fácile_Jieba斷詞在效能輸出方面,僅略遜於中研院的CKIPTagger 2.62%,對比特化繁體中文版本的Jieba提升4.89%,而在原生Jieba則是提升高達8.47%。 |
核心2 摘要分析
透過重新組建語料庫後,Fácile_GPT3 摘要在精確率效能輸出僅略遜於 ChatGPT 約略 8.818873‰,由此可知,修正後的繁體中文語料架構之正向有效性。 |
About Flowchart


About Our Tools
- Visual Studio Code開發環境
- Jieba中文斷詞
- TextRank演算法
- Openai GPT-3模組
- PyQt5圖形介面
About Our Group

|

|
| 陳禹仲 | 彭勝龍 教授 |

